
Im Normalfall wird eine Internetseite in eine Suchmaschine1 aufgenommen, wenn sich der Autor selbst in diese einträgt. Es gibt jedoch Suchmaschinen, die selbstständig die Seiten indizieren2 um ihre Datenbank zu vergrößern. Programme, die diese Arbeit verrichten, nennt man Crawler ("Spinnen"). Diese durchforsten das Internet auf neue Seiten oder aktualisieren bestehende Datensätze. Je nach Leistungsfähigkeit dieser Programme und der Hardware können täglich bis zu 20 Millionen Seiten indiziert werden. Da die Seiten nach einem Zufallsprinzip abgesucht werden, kann es Tage, aber auch Monate dauern, bis man in die Datenbank aufgenommen wird.
Hieraus ergibt sich jedoch folgendes Problem: viele bestehende Internetseiten enthalten
jedoch Informationen, die der Autor vielleicht nicht unbedingt der ganzen Welt preisgeben
will. Die Suchdienste sind jedoch auf eine größtmögliche Anzahl von Datensätze
angewiesen, um in der Gunst in der Surfer und damit auch der Sponsoren zu stehen. Ist es
aber verantwortbar, persönliche Daten ohne Rücksprache mit dem Betroffenen, der ganzen
Welt zur Verfügung zu stellen? Mit dem Datenschutzgesetz ist dies mit Sicherheit nicht
vollständig zu vereinbaren. Es stellt sich jedoch das Problem dar, daß das Internet ein
globales Medium ist, das nicht den Gesetzen der Staaten unterliegt. Außerdem ist das
Internet relativ neu, so daß sich die Justiz und die Behörden noch keine großen
Gedanken über dieses Problem gemacht haben. Jedoch wäre eine Lösung nötig. Die
Überwachung solcher Gesetze wäre praktisch nicht durchführbar, da man schlecht
nachweisen könnte, daß eine Seite ohne das Einverständnis des Autors indiziert wurde
und die Kapazitäten fehlen würden, täglich mehrere Millionen neuer Datensätze zu
überprüfen.
Im Moment muß man sich also darauf einstellen, ungewollt in eine der größten
Datenbanken aufgenommen zu werden, die für jeden zugänglich ist.
Um jedoch nicht nur leere Worte zu formulieren, kommt hier die Probe aufs Exempel:
Freundlicher Weise erklärte sich eine Versuchsperson (Name von der Redaktion geändert)
bereit, unter seinem Namen als Suchstichwort Einträge zu finden. Dabei muß natürlich
die Voraussetzung gegeben sein, daß sich die Testperson nicht bei einer Suchmaschine
schon eingetragen hat. Wir haben in fünf Suchmaschinen den Namen eingegeben:
![]() AltaVista
AltaVista
Alta Vista spuckte auf die Anfrage "Martin Rempfer" gleich einen
Link aus, der auf die Charakteristik verweist. Hier könnte man sich z. B. vorstellen,
daß Marktforscher und Werbestrategen dies nutzen um Werbung gezielt zu versenden.

![]() Excite
Excite
In Excite enthält man einen Link auf die Belwue-Startseite. Dort kann man
erfahren, welche Aufgaben der Versuchsperson zugewiesen sind.

![]() HotBot
HotBot
In HotBot gelangt man direkt zum Download-Bereich des Versuchskannikels.
Man kann sich so ein Bild über die schulischen Leistungen machen.

![]() Yahoo!
Yahoo!
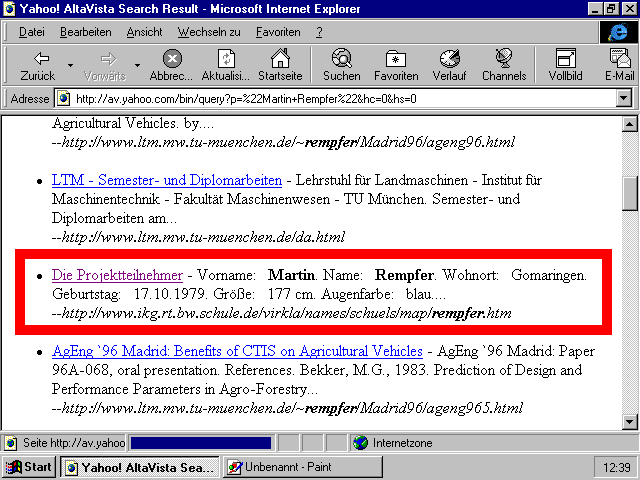
Im englischen Yahoo! gelangt man auch auf die Charakteristik.
![]() Yahoo! Deutschland
Yahoo! Deutschland
In Yahoo! Deutschland gelangt man ebenfalls auf die Charakteristik.

Wie kann man sich vor einer ungewollten Aufnahme in einen Suchdienst schützen?
Eigentlich geht dies nicht. Die Suchmaschinen untersuchen die Internetseiten auf
sogennante "meta tags" im HTML-Text. Diese enthalten Stichwörter und eine
Beschreibung. Sind diese meta-tags nicht vorhanden, so nimmt die Suchmaschine einfach
einen Teil des Textes in ihre Datenbank auf. Man könnte also in die meta-tags irgendeinen
nicht passenden Text schreiben, so daß man nicht gefunden wird.
Hier kannst Du einmal selber testen, ob Du in eine
Datenbank aufgenommen worden bist.
1 Eine sehr große Datenbank, die auf einem Internetserver läuft und für jedermann zugänglich ist. Ein Datensatz enthält Stichwörter, eine Beschreibung und die Adresse der Seite. Nach Eingabe eines Stichwortes werden zutreffende Seiten aufgelistet.
2 Aufnahme von Informationen in einen Datensatz
| mailto:Martin.Rempfer@ikg.rt.bw.schule.de | mailto:VHumorus@aol.com |